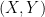El sesgo (en valor absoluto) es un cateto, la varianza es el otro cateto al cuadrado, el error cuadrático medio es la hipotenusa al cuadrado. Algunos resultados sobre variables aleatorias, muy utilizados en estadística, tienen una interpretación geométrica atractiva. La relación de la esperanza condicionada con el concepto geométrico de proyección permite adquirir intuición sobre algunos resultados y contemplarlos casi como inmediatos. En particular, la identidad ANOVA, que aparece frecuentemente asociada a diversos modelos de regresión o diseño de experimentos, se puede ver como un caso particular del teorema de Pitágoras. Aquí se da una versión poblacional de esta identidad que no está asociada a ningún modelo, sino que depende únicamente de la distribución conjunta de las variables involucradas.

Varianza, covarianza y correlación desde el punto de vista geométrico
Definir un producto escalar en el conjunto de variables aleatorias permite interpretar geométricamente varios resultados de probabilidad. El producto escalar que vamos a considerar es una medida de similaridad de las variables ya que, una vez que ajustamos por la posición y la escala, coincide con la correlación:

Como todo producto escalar, el que acabamos de introducir define una norma, que podemos considerar como una vara de medir el tamaño de una variable: 



La covarianza es el producto escalar entre las desviaciones a la media de dos variables: 

donde 




Con estas relaciones, observamos que la ley de los cosenos:

se traduce en términos probabilísticos (para las variables centradas) en la conocida igualdad

Desde este punto de vista geométrico, decir que dos variables son incorreladas es lo mismo que decir que si las centramos son perpendiculares:

La esperanza condicionada entendida como una proyección
Si queremos predecir el valor de una variable 

Una propiedad importante de esta función es la ley de la esperanza iterada
![\mathbb{E}(Y) = \mathbb{E}[\mathbb{E}(Y|X)]](https://s0.wp.com/latex.php?latex=%5Cmathbb%7BE%7D%28Y%29+%3D+%5Cmathbb%7BE%7D%5B%5Cmathbb%7BE%7D%28Y%7CX%29%5D&bg=ffffff&fg=000000&s=0&c=20201002)
que podemos entender como una fórmula de la probabilidad total para esperanzas de variables, en lugar de probabilidades de sucesos. Por ejemplo, si sabemos que 

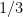
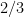

Desde el punto de vista de la predicción, si usamos
De hecho, la esperanza condicionada es, en cierto sentido, la predicción óptima ya que se puede entender como una proyección de 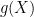
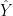


Por lo tanto, para demostrar que la esperanza condicionada es la proyección, hay que comprobar 


![\mathbb{E}[Yg(X)] = \mathbb{E}[\mathbb{E}[Y g(X)|X] = \mathbb{E}[\mathbb{E}(Y|X) g(X)].](https://s0.wp.com/latex.php?latex=%5Cmathbb%7BE%7D%5BYg%28X%29%5D+%3D+%5Cmathbb%7BE%7D%5B%5Cmathbb%7BE%7D%5BY+g%28X%29%7CX%5D+%3D+%5Cmathbb%7BE%7D%5B%5Cmathbb%7BE%7D%28Y%7CX%29+g%28X%29%5D.&bg=ffffff&fg=000000&s=0&c=20201002)
Entonces,
![\langle Y-\mathbb{E}(Y|X) , g(X)\rangle=\mathbb{E}[Yg(X)]-\mathbb{E}[\mathbb{E}(Y|X) g(X)]=0.](https://s0.wp.com/latex.php?latex=%5Clangle+Y-%5Cmathbb%7BE%7D%28Y%7CX%29+%2C+g%28X%29%5Crangle%3D%5Cmathbb%7BE%7D%5BYg%28X%29%5D-%5Cmathbb%7BE%7D%5B%5Cmathbb%7BE%7D%28Y%7CX%29+g%28X%29%5D%3D0.&bg=ffffff&fg=000000&s=0&c=20201002)
Así pues, la esperanza condicionada es la mejor predicción posible, en el sentido de minimizar la norma de la diferencia (minimiza el error cuadrático medio de predicción).
La mejor predicción lineal
¿Y qué ocurre si, por simplicidad, solo estamos dispuestos a considerar funciones lineales de 
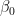
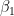

- Primera condición (perpendicularidad a 1):
. Equivalentemente, la recta que buscamos tiene que pasar por el vector de medias.
- Segunda condición (perpendicularidad a
, que se puede escribir equivalentemente como
Restándole a esta ecuación la que resulta de la primera condición mutiplicada por


Estas fórmulas son las versiones poblacionales de los parámetros de la recta de mínimos cuadrados. Aquí hemos obtenido las expresiones usando un argumento puramente geométrico.
La identidad de análisis de la varianza y el teorema de Pitágoras
Hay una identidad importante, relacionada con la varianza de una variable aleatoria, que se suele llamar identidad de análisis de la varianza (ANOVA):

En esta fórmula, la varianza condicionada se define como la usual pero condicionando a ![\mbox{Var}(Y|X) = \mathbb{E}[(Y-\mathbb{E}(Y|X))^2 |X]](https://s0.wp.com/latex.php?latex=%5Cmbox%7BVar%7D%28Y%7CX%29+%3D+%5Cmathbb%7BE%7D%5B%28Y-%5Cmathbb%7BE%7D%28Y%7CX%29%29%5E2+%7CX%5D&bg=ffffff&fg=000000&s=0&c=20201002)
Si usamos la notación 
![\mbox{Var}(Y)=\mbox{Var}(\hat{Y}) + \mathbb{E}[(Y-\hat{Y})^2].](https://s0.wp.com/latex.php?latex=%5Cmbox%7BVar%7D%28Y%29%3D%5Cmbox%7BVar%7D%28%5Chat%7BY%7D%29+%2B+%5Cmathbb%7BE%7D%5B%28Y-%5Chat%7BY%7D%29%5E2%5D.&bg=ffffff&fg=000000&s=0&c=20201002)
Esta igualdad tiene una interpretación muy clara: la varianza de una variable, la incertidumbre que tenemos sobre ella, se descompone en dos partes: la primera es la parte que 
![\mathbb{E}[(Y-\hat{Y})^2]](https://s0.wp.com/latex.php?latex=%5Cmathbb%7BE%7D%5B%28Y-%5Chat%7BY%7D%29%5E2%5D&bg=ffffff&fg=000000&s=0&c=20201002)

En esta interpretación ayuda considerar los casos extremos: si fuese 



Veamos que desde el punto de vista geométrico la identidad ANOVA no es más que el teorema de Pitágoras. Para ello basta considerar la figura siguiente:

Para interpretar la figura observamos lo siguiente:
- El triángulo es rectángulo porque, como hemos observado antes, la esperanza condicionada es la proyección de
- Que la hipotenusa al cuadrado es la varianza de
- El cateto
al cuadrado es
porque, por la ley de la esperanza iterada,
es la esperanza de
- El cateto
al cuadrado es
por la ley de la esperanza iterada, en este caso aplicada a la variable
.
Como hemos dicho antes, la identidad tal y como la hemos enunciado aquí es totalmente general ya que solo depende de la distribución conjunta de