Para la primera contribución invitada de este blog, tenemos la gran suerte de contar con una entrada escrita por José Enrique Chacón. José Enrique es profesor titular de Estadística en el Departamento de Matemáticas de la Universidad de Extremadura, miembro del Instituto de Matemáticas de esa universidad y también miembro del equipo de investigación de nuestro proyecto. Ha publicado numerosos artículos en diversos problemas estadísticos, entre los que se pueden mencionar la estimación no paramétrica de funciones de densidad y el análisis de clústeres.
En su entrada nos habla de algunas sutilezas que aparecen cuando uno trata de medir el grado en el que están de acuerdo dos expertos cuando abordan un problema de clasificación. Al final de la entrada y como reza el título, se plantea una cuestión relacionada con este asunto que lleva abierta bastantes años, por si a alguien le gustan los retos complicados…

Buscando la máxima concordancia entre particiones: un problema abierto
Es habitual encontrarnos con la situación genérica en la que se han usado dos metodologías distintas para etiquetar una serie de objetos, siendo nuestro propósito comparar las dos particiones resultantes.
Cuando las etiquetas corresponden a categorías prefijadas, con un significado concreto, estamos ante un problema de clasificación. En cambio, cuando las etiquetas se utilizan para revelar la existencia de ciertos subgrupos homogéneos, a priori ocultos dentro de un todo, entonces estamos hablando de análisis clúster.
Clasificación
Por ejemplo, podríamos pensar en dos expertos en diagnóstico que, trabajando separadamente, clasifican a un grupo de pacientes en las categorías de enfermo y sano. Cada experto proporcionará una clasificación (posiblemente distinta, pero similar) de esos pacientes, y nos gustaría cuantificar el grado de concordancia entre ambos expertos.
El primer paso a la hora de realizar dicha comparación consiste en construir lo que se llama una tabla de contingencia, que recoge el número de objetos en común de cada posible pareja de categorías. En nuestro ejemplo, esto se traduce en una tabla 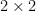
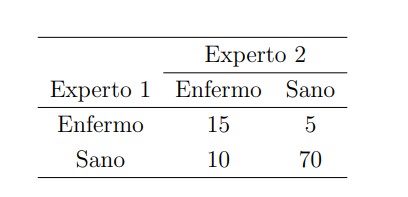
De los 100 pacientes del ejemplo, los expertos han coincidido en el diagnóstico de 15+70=85 de ellos, con lo que la proporción de concordancia observada sería 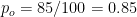

Dicha proporción observada parece ser un buen indicador del grado de acuerdo entre ambos expertos. Sin embargo, si realizamos el sencillo experimento de asignar etiquetas al azar en los dos expertos, puede sorprendernos que la proporción de concordancia resultante no es cercana a 0, sino que está en torno a 0.5. Esto ocurre porque hay un cierto grado de concordancia 
Para tener en cuenta este fenómeno, la propuesta habitual es corregir la proporción de concordancia mediante la fórmula
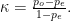
Este nuevo coeficiente, llamado kappa de Cohen, simplemente sustrae de la concordancia observada la esperada por el azar y luego normaliza para que siga valiendo 1 en el caso de concordancia perfecta. Así, un valor 
En el cálculo de 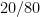
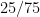
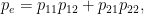
donde 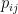


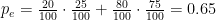

Análisis clúster
Imaginemos ahora que tenemos una serie de pacientes diagnosticados con una cierta enfermedad, y que se sospecha que entre esos casos podría haber varios subtipos de esa enfermedad. En base a ciertos análisis de los pacientes, un experto podría inferir que existen dos subgrupos distintos de personas que presentan características similares entre sí, y así concluir que en realidad los resultados ocultaban dos variantes de la enfermedad, dando lugar a una partición de los pacientes en dos grupos 
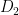
Llegaríamos entonces a construir una tabla de contingencia como la del ejemplo anterior, pero a la hora de comparar ambas particiones habría que tener en cuenta ciertas peculiaridades de esta nueva situación, que la hacen diferente del escenario previo. Sin ir más lejos, una distribución como ésta

significaría una total falta de acuerdo en el problema de clasificación, pues no contiene ningún elemento en la diagonal. Y, sin embargo, en el contexto de análisis cluster dicha tabla se corresponde con un acuerdo total entre los expertos, ya que los subgrupos que se han formado son exactamente los mismos, sólo que el primer experto ha llamado grupo 1 a los elementos que el segundo experto ha etiquetado como grupo 2, y viceversa. Esto ocurre porque a priori no existían categorías prefijadas dentro del conjunto de pacientes estudiado, sino que se han descubierto mediante su análisis.
Más aún, podría ocurrir que la metodología empleada por el segundo experto distinguiera 3 variantes de la enfermedad, en lugar de 2, en cuyo caso la tabla de contingencia sería de tipo 
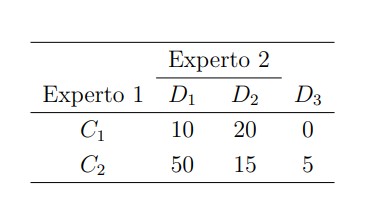
Aquí, mientras que el experto 1 sigue distinguiendo un primer grupo con 30 individuos y un segundo con 70, el experto 2 ha agrupado en una primera categoría a 60 pacientes (la mayoría de ellos, correspondientes al segundo grupo del experto 1), en una segunda categoría a 35 de ellos, y ha revelado un posible tercer grupo con 5 miembros.
En esta situación, para comparar los resultados es habitual estudiar la disposición de parejas de observaciones en ambas particiones, de modo que, sean cuales sean las dimensiones de la tabla de contingencia, sólo es necesario considerar 4 posibles situaciones: las parejas de objetos que están asignadas a un mismo grupo, en las dos particiones; o las que están en el mismo grupo en la primera partición, pero en grupos distintos en la segunda partición; o viceversa; o las parejas que están en distintos grupos en ambas particiones. Podemos llamar 




que se conoce como índice de Rand. En el ejemplo anterior, 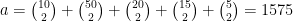
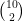
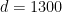

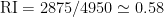
Pues bien, igual que ocurría con la proporción de concordancia en clasificación, resulta que el índice de Rand también registra cierto grado de acuerdo que se debe puramente al azar. Para corregir esta deficiencia se emplea el índice de Rand ajustado, definido como
![{\rm ARI}=\frac{{\rm RI}-\mathbb E[{\rm RI}]}{1-\mathbb E[{\rm RI}]},](https://s0.wp.com/latex.php?latex=%7B%5Crm+ARI%7D%3D%5Cfrac%7B%7B%5Crm+RI%7D-%5Cmathbb+E%5B%7B%5Crm+RI%7D%5D%7D%7B1-%5Cmathbb+E%5B%7B%5Crm+RI%7D%5D%7D%2C&bg=ffffff&fg=000000&s=0&c=20201002)
donde ![\mathbb E[{\rm RI}]](https://s0.wp.com/latex.php?latex=%5Cmathbb+E%5B%7B%5Crm+RI%7D%5D&bg=ffffff&fg=000000&s=0&c=20201002)
Y en ese mismo artículo se plantea el problema, aún abierto, al que alude el título de esta entrada. ¿Cuál es la máxima concordancia posible, ya sea medida con el 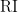

Un comentario sobre “Buscando la máxima concordancia entre particiones: un problema abierto”